
- IRIS 머신러닝 최고의 모델 찾기 -
<개요>
1. seaborn 라이브러리를 활용하여 IRIS dataset 을 로드
2. 데이터 전처리 진행
3. sklearn 에서 제공하는 여러 모델을 활용하여 학습
4. 예측 후 정확도 측정
# IRIS
IRIS 붓꽃은 4가지 특성을 가지고, 3가지 종류의 꽃을 구별하는 분류 예제이다.
# seaborn
seaborn은 matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지이다.
# sklearn
Scikit-learn은 Python 프로그래밍 언어를위한 무료 소프트웨어 기계 학습 라이브러리이다.
<코드 설명>
# 통계 / 차트를 나타내기 위한 라이브러리
import seaborn as sns
import matplotlib.pyplot as plt
# 정확도
from sklearn.metrics import accuracy_score
# 사용할 모델
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB라이브러리 import
# iris dataset load
iris = sns.load_dataset('iris')
print(iris.head(5))
print(iris.info())IRIS dataset load
생긴 것을 보아하니


데이터 갯수 : 150개
Column 갯수 : 5개
Feature 갯수 : 4개
Dtype : species 는 object 이므로, 학습시키기 전에 int형으로 전환 필요
data = iris.iloc[:, :-1] # 전체 행, 마지막 열 앞에까지
target = iris.iloc[:, -1] # 전체 행, 마지막 열
target.replace({'setosa':0,'versicolor':1,'virginica':2}, inplace=True) # 라벨 인코딩 -> 해줘야 학습 가능data 와 target 분리
# dataset 분리
train_data = data[: 120]
train_target = target[:120]
test_data = data[120:]
test_target = target[120:]train data 와 test data 분리
보통 80% 정도를 train data 로 활용하여 학습
# feature 상관관계
# hue는 색상 => 보통 target data를 서로 다른 색을 구분지어 칠하고 싶을때 사용
sns.pairplot(iris, hue='species')
plt.show()
# 모델 정의
lr = LogisticRegression()
km = KNeighborsClassifier()
svc = SVC()
gnb = GaussianNB()
model_list = [lr, km, svc, gnb]사용할 모델들을 list up
for model in model_list:
# 학습
model.fit(train_data, train_target)
# 예측
pred = model.predict(test_data)
# gt data (test_target) 과 예측결과를 비교하여 정확도 산출
print(f'사용 모델 : {model}\n예측 정확도 : {round(accuracy_score(test_target, pred), 4) * 100}%')
print()학습 및 예측, 정확도 산출
<전체 코드>
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
iris = sns.load_dataset('iris')
print(iris.head(5))
print(iris.info())
data = iris.iloc[:, :-1]
target = iris.iloc[:, -1]
target.replace({'setosa':0,'versicolor':1,'virginica':2}, inplace=True)
train_data = data[: 120]
train_target = target[:120]
test_data = data[120:]
test_target = target[120:]
sns.pairplot(iris, hue='species')
plt.show()
lr = LogisticRegression()
km = KNeighborsClassifier()
svc = SVC()
gnb = GaussianNB()
model_list = [lr, km, svc, gnb]
for model in model_list:
model.fit(train_data, train_target)
pred = model.predict(test_data)
print(f'사용 모델 : {model}\n예측 정확도 : {round(accuracy_score(test_target, pred), 4) * 100}%')
print()
<실행 화면>
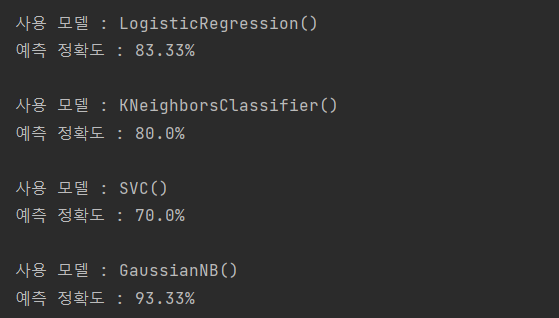
GaussianNB() 모델이 93.33%로 압도적 승리 !
- Just Do It -
반응형
'Python > Machine_learning' 카테고리의 다른 글
| [Python] CIFAR-10 (0) | 2021.07.24 |
|---|---|
| [Python] MNIST (0) | 2021.06.27 |